

Grok 4 is a large leap from Grok 3, however how good is it in comparison with different fashions out there, resembling Gemini 2.5 Professional? We now have solutions, because of new impartial benchmarks.
LMArena.ai, which is an open platform for crowdsourced AI benchmarking, has revealed the outcomes of Grok 4.
We’re speaking about Grok 4 API (grok-4-0709), which acquired about 4k+ group votes and ranks #3 total in Textual content Enviornment. This can be a enormous leap from Grok 3, which ranked eighth.
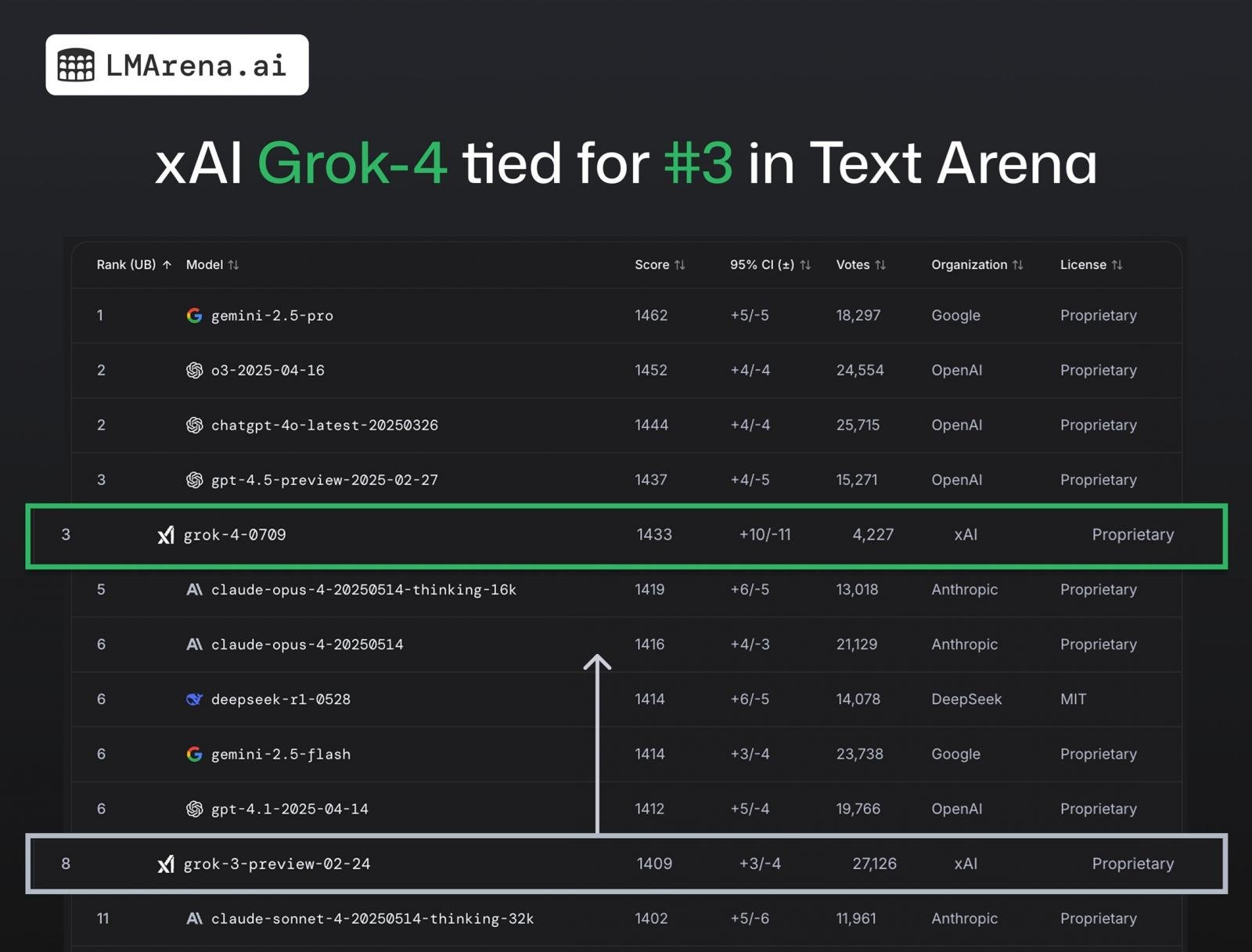
In response to LMArena’s checks, Grok 4 scores High-3 throughout all classes (#1 in Math, #2 in Coding, #3 in Exhausting Prompts).
Grok 4 was examined with real-world prompts throughout domains like coding, math, in addition to inventive writing, and it carried out very well:
- Math: #1
- Coding: #2
- Artistic Writing: #2
- Instruction Following: #2
- Exhausting Prompts: #3
Nonetheless, it’s price noting that the examined mannequin is Grok 4, not Grok 4 Heavy.
Whereas each are reasoning fashions, Grok 4 Heavy is considerably higher.
The numbers might be totally different with Grok 4 Heavy, which makes use of a number of brokers to suppose and examine outcomes, however the Grok 4 Heavy mannequin just isn’t but accessible on the API platform.
Gemini 2.5 Professional and Claude nonetheless stay one of the best fashions for coding, however that may change when xAI ships Grok 4 Code in August.
Grok 4 Code is optimised for coding, and we’re additionally anticipating a CLI, just like Gemini CLI and Claude Code.

Whereas cloud assaults could also be rising extra subtle, attackers nonetheless succeed with surprisingly easy strategies.
Drawing from Wiz’s detections throughout 1000’s of organizations, this report reveals 8 key strategies utilized by cloud-fluent menace actors.
{kind=link}