

In efficiency testing, you want loads of knowledge to get outcomes which might be significant for a manufacturing context. On this article, Sudhakar Reddy Narra explains why you shouldn’t simply give attention to the amount, but additionally on the standard of the information that you will use in your checks.
Writer: Sudhakar Reddy Narra, https://www.linkedin.com/in/sudhakar-reddy-narra-05751655/
When most individuals hear Efficiency Testing they image digital customers hammering APIs whereas graphs observe response occasions. That is only one a part of the story, however not the entire thing. The true efficiency points don’t simply come from what number of customers you simulate , however they arrive from the information these customers are working with. In case your check knowledge is just too clear, too uniform, or simply plain unrealistic knowledge, your system will look high quality in staging after which crumble below the true manufacturing workloads.
The difficulty is that manufacturing knowledge is normally off limits for efficiency testing. Safety, privateness, and compliance guidelines imply you cannot simply clone the manufacturing database and hand it for efficiency testing. That’s the place artificial knowledge is available in. For those who do it proper, it behaves like manufacturing knowledge : different, skewed, multilingual, filled with quirks , with out exposing something delicate. Executed flawed, it offers you a false sense of security in your load check.
On this article, I’ll stroll by means of learn how to generate artificial datasets that really mimic manufacturing. The bottom line is to cease pondering when it comes to uncooked document counts and begin modeling the form of knowledge, the distributions, the new spots, the time bias, the distinctiveness guidelines, and the best way folks really search. Alongside the best way, I’ll use Python’s Faker and NumPy libraries, however the ideas work irrespective of which instruments you employ.
1. Information Form Issues Extra Than Report Depend
Too many groups brag about we loaded 10 million rows into our check setting, however overlook to ask what these rows appear to be. Form is every part, excessive cardinality vs low cardinality fields, skewed recognition, recency bias, multilingual textual content, and legitimate relationships between entities. I f you ignore these, and you will notice your question plan flip from an index search in staging to a full desk scan in manufacturing.
Consider it this manner:
- Person IDs, order IDs, and emails must be actually distinctive, not simply random till they collide.
- Low cardinality fields like standing ought to comply with lifelike proportions (Ex: PAID way more widespread than CANCELLED).
- Recognition will not be really uniform, some objects get hammered whereas others hardly ever touched.
- Time will not be uniform both, most information could also be current.
- Textual content isn’t just ASCII, actual programs take care of accents, scripts, and collation guidelines.
If you mannequin these components, you reproduce the manufacturing points within the lab, the place they’re cheaper to repair.
2. A Easy Commerce Mannequin
To make this concrete, allow us to use a small schema that generalizes effectively to many programs:
- customers(user_id, e-mail, country_code, created_at)
- merchandise(product_id, sku, class)
- orders(order_id, user_id, product_id, standing, total_amount, created_at)
- search_logs(ts, user_id, query_text, filters_json)
With simply these 4 tables, you may seize uniqueness, joins, skew, recency, and lifelike search conduct. It’s sufficient to make your efficiency check significant with out drowning in complexity.
3. Recognition Skew: Why Uniform Random Fails
For those who choose customers and merchandise uniformly, your system will breeze by means of checks. In actuality, just a few VIP customers or sizzling merchandise dominate. One SKU would possibly account for 40% of gross sales, whereas 1000’s of others barely transfer. Uniformity hides these issues.
That’s the reason I take advantage of a Zipf distribution. It naturally creates sizzling spots, the preferred objects get hit repeatedly, whereas the lengthy tail isn’t touched. That is when caches begin thrashing, partitions run sizzling, and locks pile up ,precisely the sort of stress you wish to see earlier than go dwell.
4. Uniqueness: Don’t Gamble With Keys
Nothing kills a check quicker than duplicate keys sneaking in. It’s not a efficiency bug it’s a knowledge bug. As an alternative of hoping randomness doesn’t collide, construct uniqueness in by design, deterministic e-mail mills, SKU (Inventory Maintaining Unit) sequences, predictable IDs. That manner you may scale to tens of millions of rows with out worry.
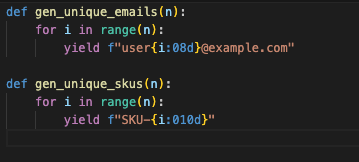
5. Customers: Reasonable Selection
Pretend customers shouldn’t all appear to be John Doe. Manufacturing customers come from in all places, and their accounts skew closely towards the current previous. In case your check knowledge doesn’t mirror that, your cache and storage patterns gained’t both.

Why hassle? As a result of clustering by time impacts indexes and cache locality, and non-English names will floor collation quirks lengthy earlier than manufacturing customers complain.
6. Merchandise: Not All Classes Are Equal
In actual commerce programs, classes are hardly ever balanced. Just a few dominate. Modeling that unevenness exposes whether or not your indexes actually assist or simply look good in principle.
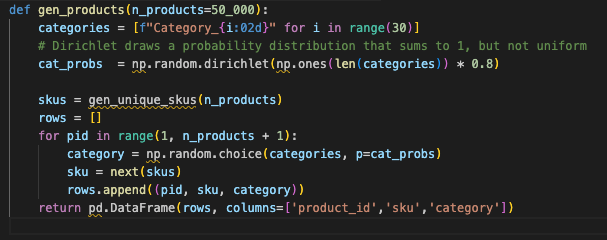
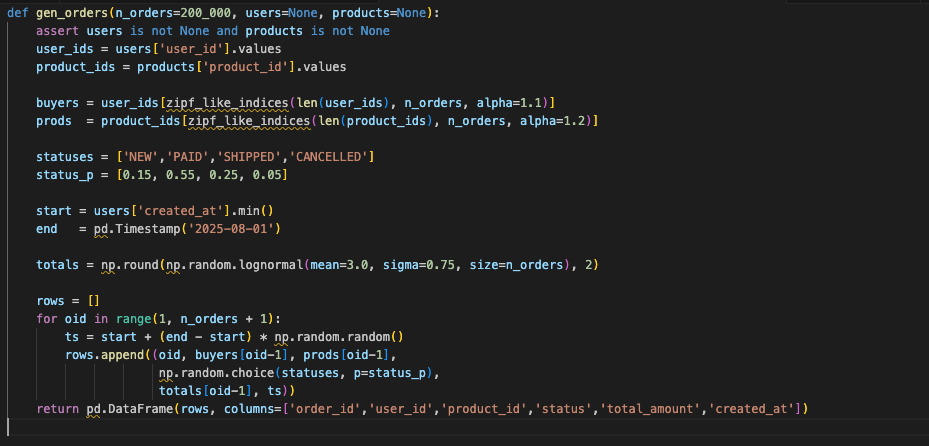
7. Orders: The place It All Comes Collectively
Orders tie the mannequin collectively and amplify skew. Use Zipf to determine who buys and what they purchase. Hold statuses lifelike (PAID dominates). Use a lognormal distribution for totals so that you get loads of small purchases and some big outliers that actually check your aggregates.
Why it issues:
- Scorching patrons and merchandise create actual lock competition.
- Standing fields stress optimizers.
- Heavy tails in totals push type and merge operators tougher than uniform values ever will.
8. Validate Earlier than You Scale
Earlier than you generate tens of millions of rows, validate. Are emails distinctive? Do overseas keys match? Are proportions roughly what you anticipate? If not, repair it now. Higher to catch it in CI than mid-load check.
9. Export for Bulk Masses
Export in codecs your datastore likes greatest – CSV for easy masses, Parquet for columnar programs. Type by time if vary queries matter. Partition by date or class in case your engine prefers it. These little selections make your check setup each quicker and extra trustworthy.

Ideas that repay instantly:
- Parquet for columnar shops (Spark, DuckDB, BigQuery).
- Pre-sort by time (created_at) when your engine advantages from clustering or when time-range filters dominate.
- Partition outputs by date/class in case your lakehouse or MPP engine prefers listing partitioning.
10. Multilingual Textual content: ASCII Received’t Save You
For those who solely check with English ASCII, you’ll miss the problems. Actual customers sort accents, non Latin scripts, and emoji. Tokenizers and collations behave in another way throughout locales. In case your check knowledge doesn’t embrace them, you might be operating an optimistic simulation.
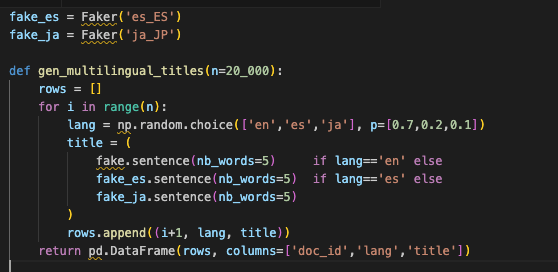
Fold these titles into search situations to validate analyzers, highlighting breakers, and question normalization.
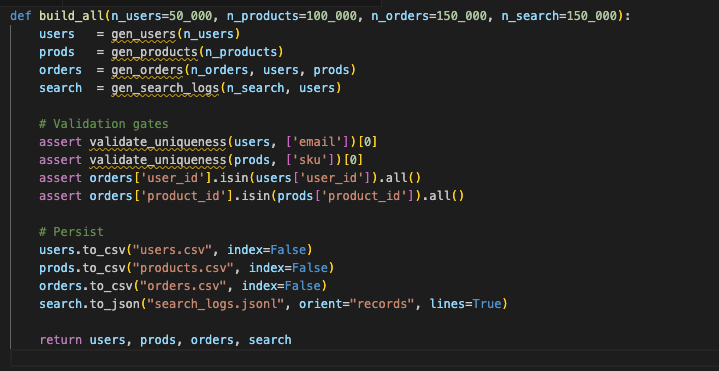
11. Orchestrate Finish-to-Finish Builds
Package deal every part behind a single operate so teammates (and CI jobs) can produce datasets constantly.
12. Widespread Pitfalls
- Utilizing uniform random in all places → appears high quality, hides hotspots.
- Small key ranges → duplicates at scale.
- No referential integrity → orphan rows crash your joins.
- Overly clear textual content → indexes and caches look higher than they’re.
- Static snapshots solely → you miss time-dependent conduct.
13. Why This Strategy Works
This technique scales down or up: begin with 50k/100k/150k rows regionally and scale to tens of tens of millions in a cluster. It turns pretend knowledge right into a sign amplifier that:
- Reproduces manufacturing solely question plans in staging
- Surfaces competition on sizzling keys and partitions
- Workout routines indexes below lifelike selectivity
- Stresses caches the best way actual visitors does
- Prevents false failures from duplicate keys and damaged FKs
Last Ideas
The most important step ahead you may soak up efficiency testing will not be including extra digital customers it’s making your knowledge extra lifelike. Cease producing random fillers, Begin producing consultant datasets that mirror the quirks of manufacturing i.e skew, recency, uniqueness, language selection. Do this, and your load check stops being a demo. It turns into a gown rehearsal you may really belief when launch day comes.
Concerning the Writer
Sudhakar Reddy Narra is a Efficiency Engineering Architect with 17+ years of expertise in designing scalable, excessive performing enterprise programs. He makes a speciality of cloud infrastructure, microservices, JVM optimization, database tuning, observability frameworks, and artificial knowledge era. His work constantly enhances scalability, reliability, and value effectivity throughout various industries and platforms.
{kind=link}