

, I current my newest open-source venture — Authorities Funding Graph.
The inspiration for this venture got here from a need to make higher tooling for grant writing, particularly to recommend analysis subjects, funding our bodies, analysis establishments, and researchers. I’ve made Innovate UK grant functions previously, so I’ve had an curiosity within the authorities funding panorama for a while.
Concretely, plenty of the current political discourse focuses on authorities spending, particularly Elon Musk’s Division of Authorities Effectivity (DOGE) in america and related sentiments echoed right here within the UK, as Kier Starmer seems to be to combine AI into authorities.
Maybe the discharge of this venture is kind of well timed. Albeit not the unique intention, I hope as a secondary final result of this text is that it evokes extra exploration into open supply datasets for public spending.
I’ve used Networkx & PyVis to visualise the graph of UKRI API information. Then, I element a LlamaIndex graph RAG implementation. For completeness, I’ve additionally included my preliminary LangChain-based answer. The net framework is Streamlit, the demo is hosted on Streamlit group cloud.
This text incorporates the next sections.
- Definitions
- UKRI API
- Assemble NetworkX Graph
- Filter a NetworkX Graph
- Graph Visualisation Utilizing PyVis
- Graph RAG Utilizing LlamaIndex
- Linting With Pylint
- Streamlit Group Cloud Demo App (on the very finish of the article)
1. Definitions
What’s UKRI?
UK Analysis and Innovation is a non-departmental public physique sponsored by the Division for Science, Innovation and Expertise (DSIT) that allocates funding for analysis and improvement. Typically, funding is awarded to analysis establishments and companies.
“We make investments £8 billion of taxpayers’ cash annually into analysis and innovation and the individuals who make it occur. We work throughout an enormous vary of fields — from biodiversity conservation to quantum computing, and from area telescopes to revolutionary well being care. We give everybody the chance to contribute and to learn, bringing collectively folks and organisations nationally and globally to create, develop and deploy new concepts and applied sciences.” — UKRI Web site
What’s a Graph?
A graph is a handy information construction exhibiting the relationships between totally different entities (nodes) and their relationships to one another (edges). In some cases, we additionally affiliate these relationships with a numerical worth.
“In laptop science, a graph is an summary information kind that’s meant to implement the undirected graph and directed graph ideas from the sector of graph principle inside arithmetic.
A graph information construction consists of a finite (and presumably mutable) set of vertices (additionally known as nodes or factors), along with a set of unordered pairs of those vertices for an undirected graph or a set of ordered pairs for a directed graph. These pairs are referred to as edges (additionally known as hyperlinks or traces), and for a directed graph are often known as edges but additionally typically arrows or arcs.” — Wikipedia

What’s NetworkX?
NetworkX is a helpful library on this venture to assemble and retailer our graph. Particularly, a digraph although the library helps many graph variants comparable to multigraphs, the library additionally helps graph-related utility features.
“NetworkX is a Python bundle for the creation, manipulation, and examine of the construction, dynamics, and features of advanced networks.” — NetworkX Web site
What’s PyVis?
We use the PyVis Python bundle to create dynamic community views for our graph, screenshots of those may be discovered all through the article.
“The pyvis library is supposed for fast technology of visible community graphs with minimal python code. It’s designed as a wrapper across the well-liked Javascript visJS library” — PyVis Docs
What’s LlamaIndex?
LlamaIndex is a well-liked library for LLM functions, together with assist for agentic workflows, we use it to carry out the graph RAG part of this venture.
“LlamaIndex (GPT Index) is a knowledge framework on your LLM utility. Constructing with LlamaIndex sometimes entails working with LlamaIndex core and a selected set of integrations (or plugins).” — LlamaIndex Github
What’s Graph RAG?

Retrieval-augmented technology, or RAG as it’s generally identified, is an AI framework for which extra context from an exterior information base is used to floor LLM solutions. Graph RAG, by extension, pertains to using a Graph to supply this extra context.
“GraphRAG is a robust retrieval mechanism that improves GenAI functions by benefiting from the wealthy context in graph information buildings… Primary RAG techniques rely solely on semantic search in vector databases to retrieve and rank units of remoted textual content fragments. Whereas this method can floor some related info, it fails to seize the context connecting these items. For that reason, fundamental RAG techniques are ill-equipped to reply advanced, multi-hop questions. That is the place GraphRAG is available in. It makes use of information graphs to symbolize and join info to seize not solely extra information factors but additionally their relationships. Thus, graph-based retrievers can present extra correct and related outcomes by uncovering hidden connections that aren’t usually apparent however are essential for correlating info.” — Neo4j Web site
What’s Streamlit?
Streamlit is a light-weight Python net framework we’ll use to create the net utility for this venture.
“Streamlit is an open-source Python framework for information scientists and AI/ML engineers to ship dynamic information apps with just a few traces of code. Construct and deploy highly effective information apps in minutes.” — Streamlit web site
2. UKRI API
The UKRI API is a service that facilitates entry to the general public UKRI grant funding dataset, authentication shouldn’t be required and the docs may be discovered right here. I take advantage of solely two endpoints for our utility, they’re the Search tasks endpoint and the Initiatives endpoint. This permits a consumer to seek for tasks based mostly on a key phrase search and retrieve all project-specific info.
A search time period, web page measurement and web page quantity are offered as question string parameters. The question string parameters;
selectedSortableField=professional.am&selectedSortOrder=DESC
Make sure that the outcomes are returned by funded worth descending.
I’ve additionally included the code I used for asynchronous pagination.
import math
import requests
import concurrent.futures
import os
from itertools import chain
import urllib.parse
import logging
def search_ukri_projects(args):
"""
Search UKRI tasks based mostly on a search time period web page measurement and web page quantity.
Extra particulars may be discovered right here: https://gtr.ukri.org/assets/api.html
"""
search_term, page_size, page_number = args
strive:
encoded_search_term = urllib.parse.quote(search_term)
if (
(
response := requests.get(
f"https://gtr.ukri.org/api/search/venture?time period={encoded_search_term}&web page={page_number}&fetchSize={page_size}&selectedSortableField=professional.am&selectedSortOrder=DESC&selectedFacets=&fields=venture.abs",
timeout=10,
)
)
and (response.status_code == 200)
and (
objects := response.json()
.get("facetedSearchResultBean", {})
.get("outcomes")
)
):
return objects
besides Exception as error:
logging.exception("ERROR search_ukri_projects: %s", error)
return []
def search_ukri_paginate(search_term, number_of_results, page_size=100):
"""
Asynchronous pagination requests for venture lookup.
"""
args = [
(search_term, page_size, page_number + 1)
for page_number in range(int(math.ceil(number_of_results / page_size)))
]
with concurrent.futures.ThreadPoolExecutor(os.cpu_count()) as executor:
future = executor.map(search_ukri_projects, args)
outcomes = [result for result in future if result]
return record(chain.from_iterable(outcomes))[:number_of_results]The next operate is used to get project-specific information utilizing the distinctive UKRI venture reference. The venture reference is derived from the aforementioned venture search outcomes.
import requests
import logging
def get_ukri_project_data(project_grant_reference):
"""
Search UKRI venture information based mostly on grant reference.
"""
strive:
if (
(
response := requests.get(
f"https://gtr.ukri.org/api/tasks?ref={project_grant_reference}",
timeout=10,
)
)
and (response.status_code == 200)
and (objects := response.json().get("projectOverview", {}))
):
return objects
besides Exception as error:
logging.exception("ERROR get_ukri_project_data: %s", error)Equally, we parse out the related information for the development of the graph and take away superfluous info.
def parse_data(tasks):
"""
Parse venture information right into a usable format and validate.
"""
information = []
for venture in tasks:
project_composition = venture.get("projectComposition", {})
project_data = project_composition.get("venture", {})
fund = project_data.get("fund", {})
funder = fund.get("funder")
value_pounds = fund.get("valuePounds")
lead_research_organisation = project_composition.get("leadResearchOrganisation")
person_roles = project_composition.get("personRoles")
if all(
[
project_composition,
project_data,
fund,
funder,
value_pounds,
lead_research_organisation,
]
):
file = {}
file["funder_name"] = funder.get("identify")
file["funder_link"] = funder.get("resourceUrl")
file["project_title"] = project_data.get("title")
file["project_grant_reference"] = project_data.get("grantReference")
file["value"] = value_pounds
file["lead_research_organisation"] = lead_research_organisation.get(
"identify", ""
)
file["lead_research_organisation_link"] = lead_research_organisation.get(
"resourceUrl", ""
)
file["people"] = person_roles
file["project_url"] = project_data.get("resourceUrl")
information.append(file)
return information3. Assemble NetworkX Graph
There are various kinds of graphs, and I elected for a directed graph the place the route of the perimeters are essential. Extra formally;
“A DiGraph shops nodes and edges with non-compulsory information, or attributes. DiGraphs maintain directed edges. Self loops are allowed however a number of (parallel) edges should not.” — NetworkX Web site
To assemble the NetworkX graph, we should add nodes and edges — together with the sequential updating of node attributes.
The usual attributes, appropriate with PyVis graph rendering for nodes are as follows;
- Title (The label that seems on hover over)
- Group (The color coding)
- Dimension (How giant the nodes seem within the graph)
We additionally use the customized attribute “funding”, which we’ll use to sum the entire funding for analysis and funding organizations. This shall be normalized to set the node measurement based on the proportion of complete funding for a selected group.
For our graph, we’ve nodes from 4 teams. They’re categorised as: funder_name, lead_research_organisation, project_title and person_name.
HTML hyperlinks can be utilized within the node title to permit the consumer to simply click on by means of to a URL. I’ve included a helper operate to do that beneath. There are venture, folks, and analysis organisation-specific hyperlinks that, if redirected to supply extra info to the consumer.
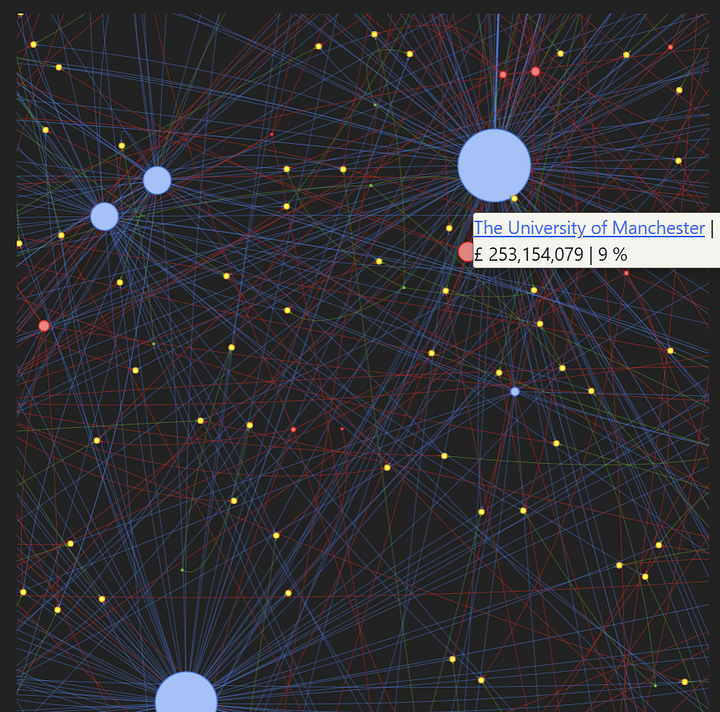
The code to assemble the NetworkX graph may be seen beneath. The DiGraph class has strategies to test if a graph already has a node and equally for edges. There are additionally strategies for including nodes and edges. As we iterate by means of tasks, we need to sum the entire funding quantity for the funding group and lead analysis establishment. There are strategies to each get an attribute from a node within the graph and set an attribute on a node. Relying on the supply and vacation spot node, we additionally apply totally different titles and labels to replicate that particular predicate. These may be seen within the code beneath.
import networkx as nx
def get_link_html(hyperlink, textual content):
"""
Helper operate to assemble a HTML hyperlink.
"""
return f"""{textual content}"""
def set_networkx_attribute(graph, node_label, attribute_name, worth):
"""
Helper to set attribute for networkx graph.
"""
attrs = {node_label: {attribute_name: worth}}
nx.set_node_attributes(graph, attrs)
def append_networkx_value(graph, node_label, attribute_name, worth):
"""
Helper to append worth to present node attribute scalar worth.
"""
current_map = nx.get_node_attributes(graph, attribute_name, default=0)
current_value = current_map[node_label]
current_value = current_value + worth
set_networkx_attribute(graph, node_label, attribute_name, current_value)
def create_networkx(information):
"""
Create networkx graph from UKRI information.
"""
graph = nx.DiGraph()
for row in information:
if (
(funder_name := row.get("funder_name"))
and (project_title := row.get("project_title"))
and (lead_research_organisation := row.get("lead_research_organisation"))
):
project_data_lookup = row.get("project_data_lookup", {})
if not graph.has_node(funder_name):
graph.add_node(
funder_name, title=funder_name, group="funder_name", measurement=100
)
if not graph.has_node(project_title):
link_html = get_link_html(
row.get("project_url", "").exchange("api/", ""), project_title
)
graph.add_node(
project_title,
title=link_html,
group="project_title",
project_data_lookup=project_data_lookup,
measurement=25,
)
if not graph.has_edge(funder_name, project_title):
graph.add_edge(
funder_name,
project_title,
worth=row.get("worth"),
title=f"{'£{:,.2f}'.format(row.get('worth'))}",
label=f"{'£{:,.2f}'.format(row.get('worth'))}",
)
if not graph.has_node(lead_research_organisation):
link_html = get_link_html(
row.get("lead_research_organisation_link").exchange("api/", ""),
lead_research_organisation,
)
graph.add_node(
lead_research_organisation,
title=link_html,
group="lead_research_organisation",
measurement=50,
)
if not graph.has_edge(lead_research_organisation, project_title):
graph.add_edge(
lead_research_organisation, project_title, title="RELATES TO"
)
append_networkx_value(graph, funder_name, "funding", row.get("worth", 0))
append_networkx_value(graph, project_title, "funding", row.get("worth", 0))
append_networkx_value(
graph, lead_research_organisation, "funding", row.get("worth", 0)
)
person_roles = row.get(
"folks", []
)
for particular person in person_roles:
if (
(person_name := particular person.get("fullName"))
and (person_link := particular person.get("resourceUrl"))
and (project_title := row.get("project_title"))
and (roles := particular person.get("roles"))
):
if not graph.has_node(person_name):
link_html = get_link_html(
person_link.exchange("api/", ""), person_name
)
graph.add_node(
person_name, title=link_html, group="person_name", measurement=10
)
for position in roles:
if (not graph.has_edge(person_name, project_title)) or (
not graph[person_name][project_title]["title"]
== position.get("identify")
):
graph.add_edge(
person_name,
project_title,
title=position.get("identify"),
label=position.get("identify"),
)
return graphAs soon as the graph has been constructed and as beforehand described, I needed to normalize the node sizes relying on the proportion of the entire quantity of funding for specific teams. I additionally append the entire funding, each as a summation and as a share to the node label so it may be extra simply considered by a consumer.
The size issue is only a a number of utilized for aesthetic causes, such that the node sizes seem relative to the opposite node teams current.
import networkx as nx
import math
import utils.config as config # pylint: disable=consider-using-from-import, import-error
def set_networkx_attribute(graph, node_label, attribute_name, worth):
"""
Helper to set attribute for networkx graph.
"""
attrs = {node_label: {attribute_name: worth}}
nx.set_node_attributes(graph, attrs)
def calculate_total_funding_from_group(graph, group):
"""
Helper to calculate complete funding for a bunch.
"""
return sum(
[
data.get("funding")
for node_label, data in graph.nodes(data=True)
if data.get("funding") and data.get("group") == group
]
)
def set_weighted_size_helper(graph, node_label, totals, information):
"""
Create normalized weights based mostly on share funding quantity.
"""
if (
(group := information.get("group"))
and (total_funding := totals.get(group))
and (funding := information.get("funding"))
):
div = funding / total_funding
funding_percentage = math.ceil(((100.0 * div)))
set_networkx_attribute(graph, node_label, "measurement", funding_percentage)
def annotate_value_on_graph(graph):
"""
Calculate normalized graph sizes and append to title.
"""
totals = {}
for group in ["lead_research_organisation", "funder_name"]:
totals[group] = calculate_total_funding_from_group(graph, group)
for node_label, information in graph.nodes(information=True):
if (
(funding := information.get("funding"))
and (group := information.get("group"))
and (title := information.get("title"))
):
new_title = f"{title} | {'£ {:,.0f}'.format(funding)}"
if total_funding := totals.get(group):
div = funding / total_funding
funding_percentage = math.ceil(((100.0 * div)))
set_networkx_attribute(
graph,
node_label,
"measurement",
config.NODE_SIZE_SCALE_FACTOR * funding_percentage,
)
new_title += f" | {' {:,.0f}'.format(funding_percentage)} %"
set_networkx_attribute(graph, node_label, "title", new_title)4. Filter a NetworkX Graph

I enable the consumer to filter nodes by way of the UI to create a subgraph. The shape to do that in Streamlit is beneath. I additionally discover the neighbors of neighbors for the filtered nodes. I had some points with Pylint elevating pointless comprehension errors from the generator, which I’ve disabled — extra on Pylint later within the article. A smaller graph will take much less time to render and can be sure that irrelevant context shall be excluded.
import networkx as nx
import streamlit as st
def find_neighbor_nodes_helper(node_list, graph):
"""
Discover distinctive node neighbors and flatten.
"""
successors_generator_array = [
# pylint: disable=unnecessary-comprehension
[item for item in graph.successors(node)]
for node in node_list
]
predecessors_generator_array = [
# pylint: disable=unnecessary-comprehension
[item for item in graph.predecessors(node)]
for node in node_list
]
neighbors = successors_generator_array + predecessors_generator_array
flat = sum(neighbors, [])
return record(set(flat))
def render_filter_form(annotated_node_data, graph):
"""
Render kind to permit the consumer to outline search nodes.
"""
st.session_state["filter"] = st.radio(
"Filter", ["No filter", "Filter results"], index=0, horizontal=True
)
if (filter_determinant := st.session_state.get("filter")) and (
filter_determinant == "Filter outcomes"
):
st.session_state["node_group"] = st.selectbox(
"Entity kind", record(annotated_node_data.keys())
)
if node_group := st.session_state.get("node_group"):
ordered_lookup = dict(
sorted(
annotated_node_data[node_group].objects(),
key=lambda merchandise: merchandise[1].get("neighbor_len"),
reverse=True,
)
)
st.session_state["search_nodes_label"] = st.multiselect(
"Filter tasks", record(ordered_lookup.keys())
)
if search_nodes_label := st.session_state.get("search_nodes_label"):
filter_nodes = [
ordered_lookup[label].get("label") for label in search_nodes_label
]
search_nodes_neighbors = find_neighbor_nodes_helper(filter_nodes, graph)
search_nodes = find_neighbor_nodes_helper(search_nodes_neighbors, graph)
st.session_state["search_nodes"] = record(
set(search_nodes + filter_nodes + search_nodes_neighbors)
)NetworkX makes it simple to create a subgraph from an inventory of nodes with the subgraph_view operate, which takes a callable as a parameter. The callable takes a graph node as a parameter and if the boolean True worth is returned, the node can be included within the subgraph.
import networkx as nx
import streamlit as st
def filter_node(node):
"""
Test to see if the filter time period is within the nodes chosen.
"""
if (
(filter_term := st.session_state.get("filter"))
and (filter_term == "Filter outcomes")
and (search_nodes := st.session_state.get("search_nodes"))
):
if node not in search_nodes:
return False
return True
graph = nx.subgraph_view(graph, filter_node=filter_node)5. Graph Visualisation Utilizing PyVis
To provide the visualizations I’ve introduced earlier within the article, we should first convert the NetworkX graph to a PyVis community after which render the HTML file inside the Streamlit UI.
If you’re unfamiliar with Streamlit, you possibly can see considered one of my different articles that discover the subject right here.
Changing a NetworkX graph to PyVis format is comparatively trivial and may be achieved with the code beneath. The Community class is the primary class for visualization performance, first we instantiate the category and on this instance, the graph is directed. The barnes_hut methodology is then known as, which is a gravity mannequin. The from_nx methodology takes an present NetworkX graph as an argument and interprets it to PyVis, which known as in place.
from pyvis.community import Community
def convert_graph(graph):
"""
Convert networkx to pyvis graph.
"""
internet = Community(
top="700px",
width="100%",
bgcolor="#222222",
font_color="white",
directed=True,
)
internet.barnes_hut()
internet.from_nx(graph)
return internetTo render the Graph to the UI, we first create a novel consumer ID as we use the PyVis save_graph methodology to save lots of the HTML file for the graph on the server. The uuid ensures a novel file identify, which is then learn into the streamlit UI and after the file is deleted.
import uuid
import contextlib
import os
import streamlit as st
def render_graphs(internet):
"""
Helper to render graph visualization from pyvis graph.
"""
uuid4 = uuid.uuid4()
file_name = f"./output/{uuid4}.html"
with contextlib.suppress(FileNotFoundError):
os.take away(file_name)
internet.save_graph(file_name)
with open(file_name, "r", encoding="utf-8") as html_file:
source_code = html_file.learn()
st.elements.v1.html(source_code, top=650, width=650)
os.take away(file_name)6. Graph RAG Utilizing LlamaIndex

Via graph retrieval-augmented technology, we are able to question our graph information immediately, an instance may be seen within the prior screenshot. Extracted entities from the consumer question are seemed up within the graph to offer particular context to the AI to floor its response, as this info would doubtless not have been within the coaching corpus, and therefore any reply given would have had an elevated probability of being a hallucination.
We create a chat engine to go a consumer’s earlier question historical past into the mannequin. Often, the Open AI API secret is learn as an setting variable inside LlamaIndex — nevertheless, since that is user-submitted for our utility and we don’t need to save customers’ Open AI credentials, we have to go credentials to the LLM and embedding mannequin courses as key phrase arguments.
We then create an empty LlamaIndex Information Graph Index and populate the information graph by inserting triples. The triples come from traversing the perimeters of our NetworkX graph and calling the upsert_triplet_and_node methodology, which is able to create the triple and node in the event that they don’t exist already.
For the reason that graph is directed, we are able to interchange the topics and objects in order that the graph is traversable in both route. The chat engine makes use of the tree_summarize possibility for the response builder.
“Tree summarize response builder. This response builder recursively merges textual content chunks and summarizes them in a bottom-up trend (i.e. constructing a tree from leaves to root). Extra concretely, at every recursively step: 1. we repack the textual content chunks so that every chunk fills the context window of the LLM 2. if there is just one chunk, we give the ultimate response 3. in any other case, we summarize every chunk and recursively summarize the summaries.”— LlamaIndex Web site
Calling the chat methodology with the consumer’s question and setting up the chat historical past from the Streamlit state object is included right here.
from llama_index.core import KnowledgeGraphIndex
from llama_index.core.schema import TextNode
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage, MessageRole
import streamlit as st
import utils.ui_utils as ui_utils # pylint: disable=consider-using-from-import, import-error
def init_llama_index_graph(graph_nx, open_ai_api_key):
"""
Assemble a information graph utilizing llama index.
"""
llm = OpenAI(mannequin="gpt-3.5-turbo", api_key=open_ai_api_key)
embed_model = OpenAIEmbedding(api_key=open_ai_api_key)
graph = KnowledgeGraphIndex(
[], llm=llm, embed_model=embed_model, api_key=open_ai_api_key
)
for subject_entity, object_entity in graph_nx.edges():
predicate = graph_nx[subject_entity][object_entity].get("label", "pertains to")
graph.upsert_triplet_and_node(
(subject_entity, predicate, object_entity), TextNode(textual content=subject_entity)
)
graph.upsert_triplet_and_node(
(object_entity, predicate, subject_entity), TextNode(textual content=subject_entity)
)
chat_engine = graph.as_chat_engine(
include_text=True,
response_mode="tree_summarize",
embedding_mode="hybrid",
similarity_top_k=5,
verbose=True,
llm=llm,
)
return chat_engine
def add_result_to_state(query, response):
"""
Add mannequin output to state.
"""
if response:
graph_answers = st.session_state.get("graph_answers") or []
graph_answers.append((query, response))
st.session_state["graph_answers"] = graph_answers
else:
st.error("Question failed, please strive once more later.", icon="⚠️")
def query_llama_index_graph(query_engine, query):
"""
Question llama index information graph utilizing graph RAG.
"""
graph_answers = st.session_state.get("graph_answers", [])
chat_history = []
for question, reply in graph_answers:
chat_history.append(ChatMessage(position=MessageRole.USER, content material=question))
chat_history.append(
ChatMessage(position=MessageRole.ASSISTANT, content material=reply)
)
if response := query_engine.chat(query, chat_history):
add_result_to_state(query, response.response)Equally, I initially explored a LangChain implementation, although throughout some experimentation, I made a decision to proceed wth the LlamaIndex-based method beforehand demonstrated. For reference, I’ve included this beneath whether it is helpful to you.
Within the curiosity of brevity, the reason is omitted, although it must be self-explanatory for the reader.
from langchain_community.chains.graph_qa.base import GraphQAChain
from langchain_community.graphs import NetworkxEntityGraph
from langchain_community.graphs.networkx_graph import KnowledgeTriple
from langchain_openai import ChatOpenAI
import streamlit as st
def add_result_to_state(query, response):
"""
Add mannequin output to state.
"""
if response:
graph_answers = st.session_state.get("graph_answers") or []
graph_answers.append((query, response))
st.session_state["graph_answers"] = graph_answers
else:
st.error("Question failed, please strive once more later.", icon="⚠️")
def construct_graph_langchain(graph_nx, open_ai_api_key, query):
"""
Assemble a information graph in Langchain and preform graph RAG.
"""
graph = NetworkxEntityGraph()
for node in graph_nx:
graph.add_node(node)
for subject_entity, object_entity in graph_nx.edges():
predicate = graph_nx[subject_entity][object_entity].get("label", "pertains to")
graph.add_triple(KnowledgeTriple(subject_entity, predicate, object_entity))
llm = ChatOpenAI(
api_key=open_ai_api_key, mannequin="gpt-4", temperature=0, max_retries=2
)
chain = GraphQAChain.from_llm(llm=llm, graph=graph, verbose=True)
if response := chain.invoke({"question": query}):
reply = response.get("end result")
add_result_to_state(query, reply)7. Linting With Pylint

Since I’ve left some feedback within the code to disable the linter within the examples above (examples are referenced from the GitHub repo), I assumed I’d cowl the subject of linting briefly.
For these unfamiliar, linting helps to test your code for potential bugs and stylistic points. Linters routinely implement coding requirements.
To get began, set up Pylint by working the command.
pip set up pylintSecondly, we have to create a .pylintrc file on the root of the venture (we are able to additionally set default world and user-specific settings relying on the place we create the .pylintrc file). To do that, you’ll need to run.
pylint --generate-rcfile > .pylintrcWe are able to configure this file to suit our preferences by updating the default values inside the .pylintrc file.
To run the linter manually, you need to use.
pylint ./most important.py && pylint ./**/*.pyWhen the Docker picture is constructed, it can routinely run Pylint and lift an error ought to it detect a problem with the code. This may be seen within the Dockerfile.
FROM python:3.10.16 AS base
WORKDIR /app
COPY necessities.txt .
RUN pip set up --upgrade pip
RUN pip set up -r necessities.txt
COPY . .
RUN mkdir -p /app/output
RUN pylint ./most important.py && pylint ./**/*.py
RUN python -m unittest -v checks.test_ukri_utils.Testing
CMD ["streamlit", "run", "./main.py"]A well-liked formatter that you may also discover helpful is Black —
“Black is a PEP 8 compliant opinionated formatter. Black reformats complete recordsdata in place.”
Working Black will routinely resolve a few of the points that will be raised by the linter.
8. Streamlit Group Cloud Demo App
With Streamlit Group Cloud, anybody can host their utility at no cost. When you have an utility you’d prefer to deploy, you possibly can comply with this tutorial.
To see the hosted demo, please click on the hyperlink beneath.
https://governmentfundinggraph.streamlit.app
Thanks for studying my article — as promised, you could find all of the code within the GitHub repo right here.
Any and all suggestions is effective to me because it supplies route for my future tasks. If you happen to discovered this text helpful, please let me know.
You may also discover me over on LinkedIn if in case you have particular questions.
Concerned with open-source AI grant writing tasks? Join our mailing record right here.
*All photographs, except in any other case famous, are by the writer.
{kind=link}