
ChatGPT 4.1 is now rolling out, and it is a important leap from GPT 4o, nevertheless it fails to beat the benchmark set by Google Gemini.
Yesterday, OpenAI confirmed that builders with API entry can strive as many as three new fashions: GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano.
In line with the benchmarks, these fashions are much better than the present GPT‑4o and GPT‑4o mini, notably in coding.
For instance, GPT‑4.1 scores 54.6% on SWE-bench Verified, which is healthier than GPT-4o by 21.4% and 26.6% over GPT‑4.5. Now we have related outcomes on different benchmarking instruments shared by OpenAI, however how does it compete in opposition to Gemini fashions.
ChatGPT 4.1 early benchmarks
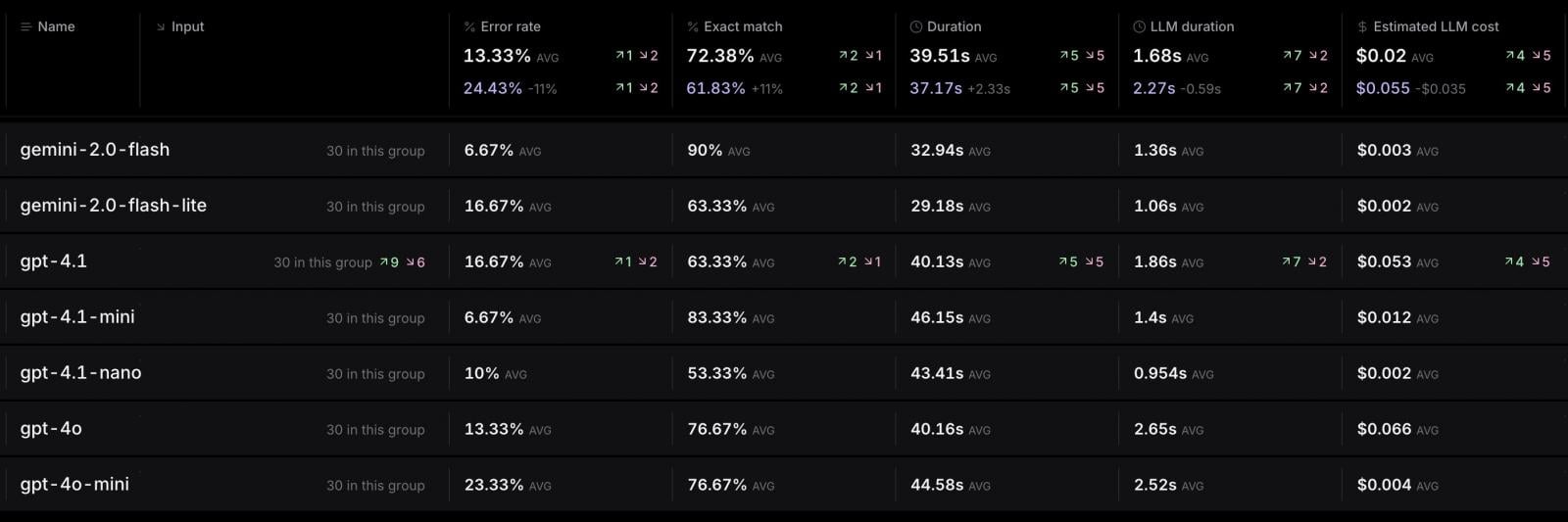
In line with benchmarks shared by Stagehand, which is a production-ready browser automation framework, Gemini 2.0 Flash has the bottom error price (6.67%) together with the best precise‑match rating (90%), and it’s additionally low-cost and quick.
Alternatively, GPT‑4.1 has a better error price (16.67%) and prices over 10 occasions greater than Gemini 2.0 Flash.
Different GPT variants (like “nano” or “mini”) are cheaper or sooner however not as correct as GPT-4.1
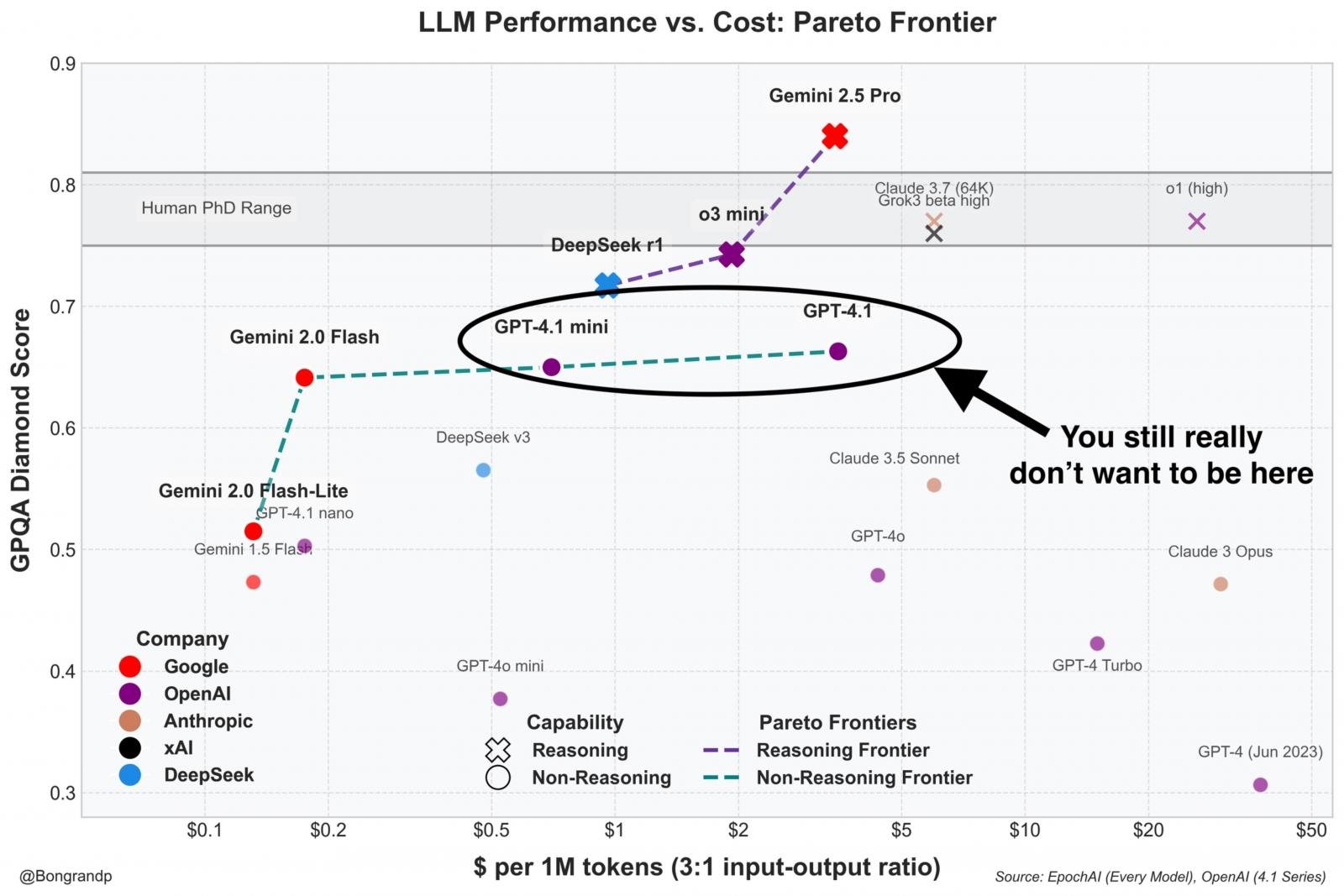
In one other information shared by Pierre Bongrand, who’s a scientist engaged on RNA at Harward, GPT‑4.1 affords poorer cost-effectiveness than competing fashions.
This is a vital issue as a result of GPT4.1 is cheaper than ChatGPT 4o.
Fashions like Gemini 2.0 Flash, Gemini 2.5 Professional, and even DeepSeek or o3 mini lie nearer to or on the frontier, which suggests they ship greater efficiency at a decrease or comparable price.
In the end, whereas GPT‑4.1 nonetheless works as an possibility, it is clearly overshadowed by cheaper or extra succesful alternate options.
Coding benchmarks present GPT-4.1 lags behind Gemini 2.5
.jpg)
We’re seeing related leads to coding benchmarks, with Aider Polyglot itemizing GPT-4.1 with a 52% rating, whereas Gemini 2.5 is miles forward at 73%.
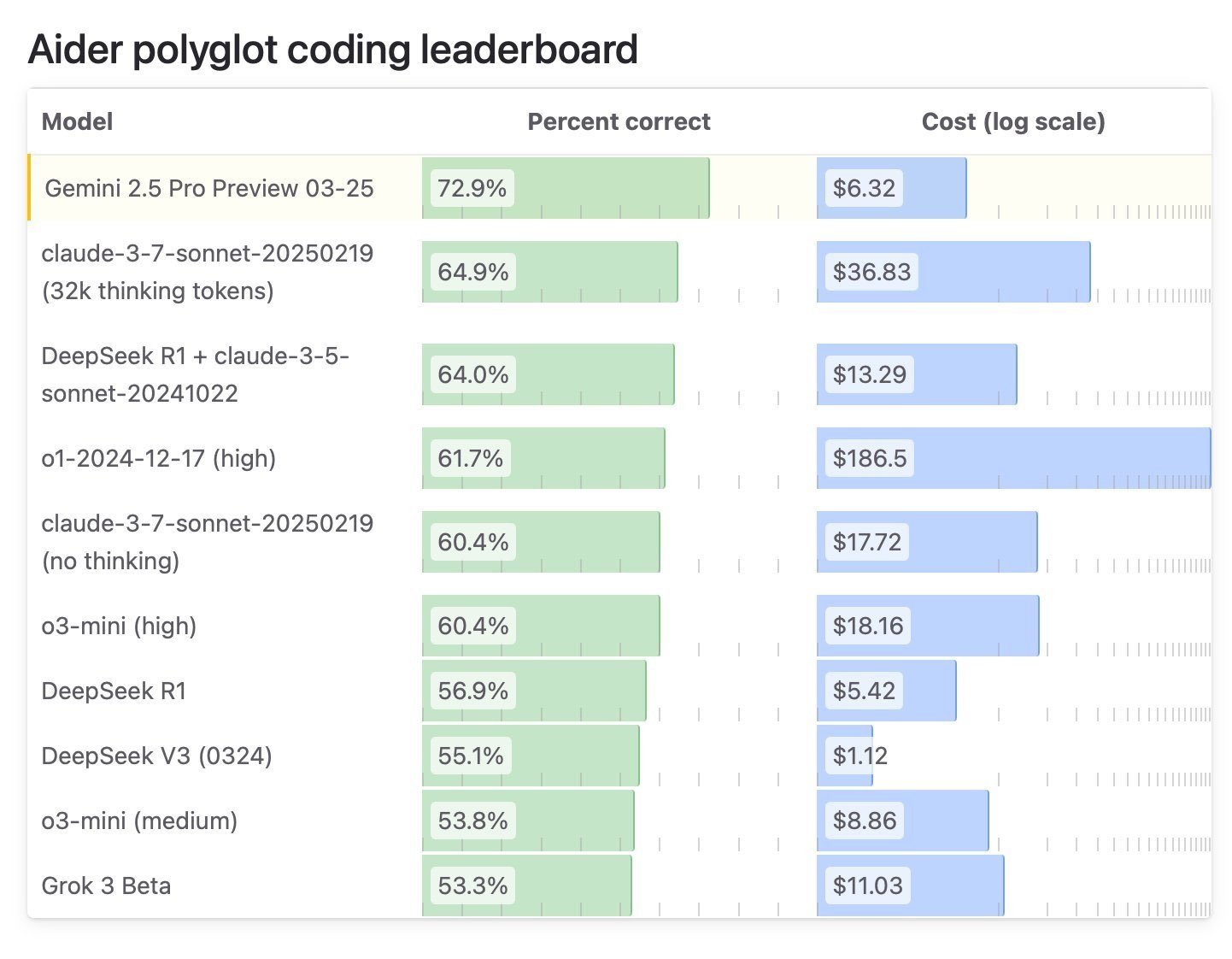
It is usually essential to notice that GPT-4.1 is a non-reasoning mannequin, and it is nonetheless top-of-the-line fashions for coding.
GPT-4.1 is offered by way of API, however you need to use it at no cost if you happen to join Windsurf AI.
{kind=link}